
Содержание
Введение. Функции алгебры логики.
Разложение функций по переменным. Совершенная дизъюнктивная нормальная форма.
Выводы по первым двум темам. СКНФ.
Разрешимoсть задач в классической теории алгоритмов.
Трудоемкость алгоритмов.
Память и время как количественная характеристика алгоритма. (применительно к машине Тьюринга и современным ЭВМ).
Трудоемкость алгоритма на примере RSA, квантовые компьютеры.
Вывод.
Введение. Функции алгебры логики
Любая формула алгебры логики зависит от переменных высказываний x1 , x2 ... xn , полностью определяющих значение входящих в неё простых высказываний, следовательно, её можно рассматривать как функцию этих высказываний. Такие функции, которые как и их переменные принимают значение “0” или “1”, называют функциями алгебры логики или логическими функциями. Эти функции обозначаются f(x1 ... xn ).
Логическая переменная может принимать два значения, тогда из n-переменных можно составить N= 2n комбинаций из “0” и “1”, которые принято называть наборами переменных, и говорят, что функция f определена на множестве наборов. Посколько функция принимает два значения, то на N наборов можно построить M= mN различных функций.
Пример. Если n=1, то наборов N=2, а функций M=4
n=2 N=4 M=16
n=4 N=8 M=256
Элементарные функции - логические функции одной или двух переменных.
Постороим при n=1 функцию f(x).
| X | f1 | f2 | f3 | f4 |
| 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 1 | 0 |
Здесь f1 (x)=0 – константа “0”;
f2 (x)= 1 – константа “1”;
f3 (x)= x – функция x
f5 (x)= Øx – отрицание.
Аналогично, при n=2 получаем:
f5 (x,y)=xÈy
f6 (x,y)=x×y
f7 (x,y)=x®y
f8 (x,y)=y®x
f10 (x,y)= Ø f9 (x,y)=xÅy – сумма по модулю “два”.
f11 (x,y)=Øf10 (x,y)=x½y – Штрих Шеффера.f9 (x,y)=x~yf12 (x,y)=Øf5 (x,y)=x¯y – стрелка Пирса.
Таким образом, при возрастании числа переменных, число строк значительно увеличивается, поэтому чаще используют задание в виде логической функции – такая запись называется аналитической.
Разложение функций по переменным. Совершенная дизъюнктивная нормальная форма.
Введем обозначение x0 =Øx, x1 =x. Пусть а - параметр, равный 0 или 1. Тогда xA =1, если x=а, и xA =0, если х¹а.
Теорема. Всякая логическая функция f(x1 , ... , xn ) мо-жет быть представлена в следующем виде:
![]()
где n³m, а дизъюнкция берется по всем 2m наборам значений переменных х1 , ..., хm .
Это равенство называется разложением по переменным х1 , ..., хт . Например, при n=4, m=2 разложение имеет вид:
f(x1 , x2 , x3 , x4 )= Øx1 Øx2 f(0, 0, x3 , x4 ) ÈØx1 x2 f & (0,1,x3 ,x4 )È x1 Øx2 f(1,0,x3 ,x4 )È x1 x2 f(1,1,x3 ,x4 )
Теорема доказывается подстановкой в обе части равенства произвольного набора всех п переменных.
При m=1 из получаем разложение функции по одной переменной
![]()
Ясно, что аналогичное разложение справедливо для любой из п переменных. Другой важный случай — разложение по всем п переменным (т=п). При этом все переменные в правой части (3.4) получают фиксированные значения и функции в конъюнкциях правой части становятся равными 0 или 1, что дает:
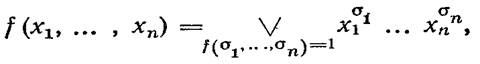
где дизъюнкция берется по всем наборам ![]() на которых f=1. Такое разложение называется совершенной дизъюнктивной нормальной формой (СДНФ) функции f. СДНФ функции f содержит ровно столько конъюнкций, сколько единиц в таблице f ; каждому единичному набору
на которых f=1. Такое разложение называется совершенной дизъюнктивной нормальной формой (СДНФ) функции f. СДНФ функции f содержит ровно столько конъюнкций, сколько единиц в таблице f ; каждому единичному набору ![]() соответствует конъюнкция всех переменных, в которой Xiвзято с отрицанием, если si
= 0, и без отрицания, если si
= l. Таким образом, существует взаимно однозначное соответствие между таблицей функции f (x1
, ..., хп
) и ее СДНФ, и, следовательно, СДНФ для всякой логической функции единственна (точнее, единственна с точностью до порядка букв и конъюнкций: это означает, что ввиду коммутативности дизъюнкции и конъюнкции формулы, получаемые из предыдущей формулы перестановкой конъюнкций и букв в конъюнкции, не различаются и считаются одной и той же СДНФ). Единственная функция, не имеющая СДНФ – это константа 0.
соответствует конъюнкция всех переменных, в которой Xiвзято с отрицанием, если si
= 0, и без отрицания, если si
= l. Таким образом, существует взаимно однозначное соответствие между таблицей функции f (x1
, ..., хп
) и ее СДНФ, и, следовательно, СДНФ для всякой логической функции единственна (точнее, единственна с точностью до порядка букв и конъюнкций: это означает, что ввиду коммутативности дизъюнкции и конъюнкции формулы, получаемые из предыдущей формулы перестановкой конъюнкций и букв в конъюнкции, не различаются и считаются одной и той же СДНФ). Единственная функция, не имеющая СДНФ – это константа 0.
Формулы, содержащие, кроме переменных (и, разумеется, скобок), только знаки функций дизъюнкции, конъюнкции и отрицания, будем называть булевыми формулами (напомним, что знак конъюнкции, как правило, опускается). Предыдущая формула приводит к важной теореме.
Теорема. Всякая логическая функция может быть представлена булевой формулой, то есть как суперпозиция конъюнкции, дизъюнкции и отрицания.
Действительно, для всякой функции, кроме константы 0, таким представлением может служить её СДНФ. Константу 0 можно представить булевой формулой Ø xx.
А почему же формула называется “совершенной”? Совершенной называется потому, что она имеет 4 свойства совершенства.
1. В формуле все конъюнкции разные.
2. В конъюнкции все переменные разные.
3. В одной конъюнкции не встречаются переменные вместе с их отрицанием.
4. В конъюнкции столько переменных, сколько в исходной функции f , то есть n. (Число переменных в функции есть ранг этой функции).
В таблице истинности определяют единичные наборы. Из переменных образуют конъюнкции следующим образом: если переменная = 1, то пишем x, если ¹ 1, то пишем Øx. Полученные конъюнкции объединяем знаком дизъюнкции.
| x | y | Z | f | |
| 0 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | |
| 0 | 1 | 0 | 0 | |
| 0 | 1 | 1 | 1 | Ø xyz |
| 1 | 0 | 0 | 0 | |
| 1 | 0 | 1 | 1 | x Ø yz |
| 1 | 1 | 0 | 1 | xy Ø z |
| 1 | 1 | 1 | 1 | xyz |
В результате получаем следующую СДНФ:
f(x, y, z) = (Ø xyz) È (x Ø yz) È (xy Ø z) È (xyz)
Выводы по первым двум темам.
Логическая переменная может принимать два значения, тогда из n-переменных можно составить N= 2n комбинаций из “0” и “1”, которые принято называть наборами переменных, и говорят, что функция f определена на множестве наборов. Поскольку функция принимает два значения, то на N наборов можно построить M= mN различных функций. Становится очевидно, что чем больше переменных содержит функция, тем более громоздкой становится таблица истинности. Поэтому чаще используют аналитическую форму записи. Но машинам (тем же ЭВМ) непонятна такая форма записи и всё равно необходимо строить таблицы истинности, что порою может отнимать значительно времени. Об этом речь пойдет чуть ниже.
Так же бывает проблематично, а порою даже и невозможно построить СДНФ не использую таблицы истинности.
Так же существует СКНФ – Совершенная Конъюнктивная Нормальная Формула. Я не стал останавливаться на ней более подробно, так как она очень похожа на СДНФ, с той лишь разницей, что состоит из конъюнктивных элементов дизъюнкции. Соответствующие изменения будут и при получении СКНФ из таблицы истинности.
| x | Y | Z | f | |
| 0 | 0 | 0 | 0 | хÈyÈz |
| 0 | 0 | 1 | 0 | xÈyÈØz |
| 0 | 1 | 0 | 0 | xÈØyÈz |
| 0 | 1 | 1 | 1 | |
| 1 | 0 | 0 | 0 | ØxÈ yÈ z |
| 1 | 0 | 1 | 1 | |
| 1 | 1 | 0 | 1 | |
| 1 | 1 | 1 | 1 |
Таким образом получаем следующую СКНФ:
f(x,y,z)=(хÈyÈz)^(xÈyÈØz)^(xÈØyÈz)^(ØxÈyÈz)
Разрешим o сть задач в классической теории алгоритмов
В классической теории алгоритмов задача считается разрешимой, если существует решающий ее алгоритм. Однако для реализации некоторых алгоритмов при любых разумных с точки зрения физики предположениях о скорости выполнения элементарных шагов может потребоваться больше времени, чем по современным воззрениям существует вселенная. Поэтому возникает потребность конкретизировать понятие разрешимости и придать ему оценочный, количественный характер, введя такие характеристики алгоритмов, которые позволяли бы судить о возможности и целесообразности их практического применения.
Среди различных возможных характеристик алгоритмов наиболее важными с прикладной точки зрения являются две: время и память, расходуемые при вычислении. Физическое время вычисления алгоритма характеризуется произведением tt, где t - число действий (шагов) вычисления, а t - среднее физическое время реализации одного шага. Число шагов t определяется описанием алгоритма в данной алгоритмической модели, это - величина математическая, не зависящая от особенностей физической реализации модели. Напротив, t зависит от реализации и определяется скоростью обработки сигналов в элементах, записи и считывания информации и т. д. Поэтому число действий t можно считать математическим временем вычисления алгоритма, определяющим физическое время вычисления с точностью до константы t, зависящей от реализации.
Память как количественная характеристика алгоритма
Память как количественная характеристика алгоритма определяется количеством S единиц памяти (ячеек ленты машины Тьюринга или машинных слов в современных ЭВМ), используемых в процессе вычисления алгоритма. Ясно, что эта величина по порядку не может превосходить числа шагов вычисления: mt³s, где m - максимальное число единиц памяти, используемых в данной машине на одном шаге. Напротив, t может существенно превосходить s, например, возможно соотношение t ³ s^c. С этой точки зрения время более тонко отражает сложность алгоритма, чем память; и это - одна из причин, по которой исследованию временных характеристик алгоритма уделяется большее внимание. Существуют и другие, прикладные причины (в частности, то, что, грубо говоря, память дешевле времени), которые здесь обсуждаться не будут. Так или иначе, здесь будет идти речь о трудоемкости алгоритмов и задач, решаемых алгоритмами.
Итак, трудоемкость алгоритма - это число элементарных действий, выполненных при его вычислении.
Полной характеристикой конкретного варианта задачи является его формальное описание. Характеристикой сложности описания можно считать его объем, который иногда называют размерностью задачи (например, для изоморфизма графов размерностью задачи можно считать число символов в матрицах смежности графов); тогда исследование трудоемкости алгоритма рассматривается как исследование зависимости трудоемкости вычисления от размерности задачи, решаемой алгоритмом.
И в математике, и на практике в конечном счете нас интересуют не алгоритмы сами по себе, а задачи, которые они решают. Одна и та же задача может решаться различными алгоритмами и на разных машинах. Если машина М зафиксирована, то трудоемкостью данной задачи относительно машины М называется минимальная из трудоемкостей алгоритмов, решающих задачу на машине М. Задач, трудоемкость которых была бы определена точно, довольно мало; хорошим результатом считается определение ее по порядку, т. е. с точностью до множителя, ограниченного некоторой константой. Чаще удается оценить ее сверху или снизу. Оценку сверху получают, указав конкретный алгоритм решения задачи: по определению, трудоемкость задачи не превосходит трудоемкости любого из решающих ее алгоритмов. Оценки трудоемкости снизу - гораздо более трудное дело; их получают обычно из некоторых общих соображений (например, мощностных или информационных). О них здесь говорить не будем.
Можно ли говорить об инвариантности теории трудоемкости вычислений? Иначе говоря, возможны ли утверждения о трудоемкости вычислений, сохраняющиеся при переходе к любой алгоритмической модели? Что касается прямых количественных оценок, то инвариантами не являются не только константы, но и степени. Например, доказано, что трудоемкость распознавания симметричности слова длины п относительно его середины на машине Тьюринга не меньше, чем сn^2, тогда как для любой ЭВМ, имеющей доступ к памяти по адресу, допускающей операции над адресами, легко написать программу, решающую эту задачу с линейной трудоемкостью.
Таким образом, скорости вычислений на разных моделях различны. Однако строить теорию трудоемкости вычислений, привязываясь к некоторым конкретным моделям, неудобно ни для теории, ни для практики. Для теории - потому, что такая привязка не дает достаточно объективных характеристик трудоемкости задачи, т. е. не позволяет отделить влияние особенностей выбранной модели от специфики самой задачи; для практики - потому, что разнообразие реальных машин растет, и нужны общие понятия и методы оценки трудоемкости решения задач, которые сохраняют свою силу при любых изменениях в мире компьютеров. Поэтому инвариантная теория трудоемкости нужна, и вопрос не в том, возможна ли она, а в том, как ее построить (т. е. какие инварианты найти). Для того чтобы обсуждать этот вопрос, прежде всего следует посмотреть, как меняется трудоемкость при переходе от одной машины к другой. Это рассмотрение мы начнем с некоторого краткого обзора парка абстрактных машин, о которых будет идти речь.
До сих пор в явном виде была описана только одна абстрактная машина - машина Тьюринга. Однако неявно использовалась машина другого типа, гораздо более близкая к современным ЭВМ, в которой возможен доступ к памяти по адресам. Такая машина, называе-мая машиной с произвольным доступом к памяти, может на следующем шаге переходить к любой ячейке с указанным адресом (команды условного и безусловного переходов) и реализовать команды-операторы. Возможны различные варианты моделей машины с произвольным доступом к памяти; в более сложных вариантах допускаются операции над адресами. Здесь мы не будем рассматривать все эти варианты, ограничившись фиксацией лишь одной простой модели - машины элементарных логических операций, или кратко L-машины. Относительно других моделей абстрактных машин ограничимся констатацией их основных свойств, которых будет достаточно при последующих рассмотрениях. Будем считать, что каждая машина имеет конечное число устройств (головок, устройств управления головками, процессоров- устройств, выполняющих элементарные операции, и т. д.), каждое устройство и каждая ячейка памяти могут находиться в одном из конечного числа возможных состояний (состояние ячейки памяти - это записанный в ней символ), и выполнение любого элементарного действия (шага) зависит от информации из конечного числа ячеек памяти, ограниченного некоторой константой m. Будем говорить, что все ячейки читаются на данном шаге. Полное состояние машины, т. е. набор состояний устройств, состояний ячеек памяти и указание ячеек, читаемых в настоящий момент, называется конфигурацией машины.
И наконец, еще одно вступительное замечание. Алгоритм, осуществляемый машиной, может быть реализован двояким образом: он может быть "встроен" в управляющее устройство или записан в памяти машины. В первом случае машина является специализированной и может выполнять только данный алгоритм; чтобы изменить алгоритм, надо поменять управляющее устройство. Таковы машины Тьюринга. Во втором случае запись алгоритма в памяти называется программой, а сама машина - программируемой; алгоритм, встроенный в управляющее устройство, решает задачу исполнения программ, записанных в памяти машины. Такова универсальная машина Тьюринга и все реальные универсальные ЭВМ. В обоих случаях начальная конфигурация машины - состояния всей памяти и всех устройств - полностью определяет процесс вычисления.
Машина элементарных логических операций (L-машина) - это машина с произвольным доступом к памяти, имеющая следующую систему команд:
X:=0;
X:=1;
X:=y;
X:=Ø y;
X:= y & z;
X:= y È z;
“конец”
Где x, y, z – адреса ячеек памяти, := - знак присвоения.
В принципе, современные компьютеры примерно так и работают, производят манипуляции с ячейками памяти, некоторые действия.
Трудоемкость алгоритма на примере RSA , квантовые компьютеры
RSA – алгоритм шифрования с открытым ключом
Всегда поднималась проблема о безопасной передаче информации. Любая линия, по которой идет передача информации может быть прослушана, и информация может попасть к злоумышленнику. Нужен был надежный алгоритм шифрования. Сообщение можно было зашифровать каким-либо ключом и передать сообщение, а затем и ключ, но при этом всё равно оставалось возможным перехватить ключ и расшифровать сообщение. В 1970-ых годах для решения этой проблемы были предложены системы шифрования, использующие два вида ключей для одно и того же сообщения: открытый (не требующий хранения в тайне) и закрытый (строго секретный). Открытый ключ служит для зашифровки сообщений, а закрытый для его дешифровки. Вы посылаете вашему корреспонденту открытый ключ, он с помощью него шифрует сообщение и отправляет его вам. Всё, что сможет сделать злоумышленник, перехватив ключ, - это зашифровать им своё письмо и отправить его кому либо. Но расшифровать переписку он не сможет, для этого необходим закрытый ключ. Как раз такая схема и применяется в алгоритме RSA. Причем для создания пары открытого и закрытого ключа используется следующая гипотеза. Если имеется два больших (требующих больше сотни десятичных цифр для своей записи) простых числа M и K, то найти их произведение N=M*K не составит большого труда. А вот решить обратную задачу, то есть зная число большое N разложить его на простые множители M и K (так называемая задача факторизации) – практически невозможно! Именно с этой проблемой сталкивается злоумышленник, решивший “взломать” алгоритм RSA и прочитать зашифрованную с помощью него информацию: чтобы узнать закрытый ключ, зная открытый, придется вычислить M или K.
Для проверки справедливости гипотезы о практической сложности разложения на множители больших чисел проводились и до сих пор проводятся конкурсы. Рекордом считается разложение 155-значного (512-битного) числа. Вычисления велись параллельно на многих компьютерах в течении семи месяцев 1999 года. Расчеты показывают, что с использованием даже тысячи современных рабочих станций и лучшего из известного на сегодня алгоритмов одно 250-значное число может быть разложено на множители примерно за 800 тысяч лет, а 1000 значное – за 1025 лет. (для сравнения возраст Вселенной ~ 1010 лет.).
Поэтому криптографические алгоритмы, подобные RSA, оперирующие достаточно длинными ключами, считались абсолютно надежными и использовались во многих приложениях. Пока не были придуманы квантовые компьютеры.
Оказывается, используя законы квантовой механики, можно построить такие компьютеры, для которых задача факторизации не составит большого труда. Согласно оценкам, квантовый компьютер с памятью объемом всего лишь в 10 тысяч квантовых битов способен разложить 1000-значное число на простые множители всего за несколько часов.
По мере распространения компьютеров ученые, занимавшиеся квантовыми объектами, пришли к выводу о невозможности рассчитать состояние эволюционирующей системы, состоящей всего из десятков взаимодействующих частиц, например молекул метана. Объясняется это тем, что для полного описания сложной системы необходимо держать в памяти компьютера очень большое количество переменных, так называемых квантовых амплитуд. Возникла парадоксальная ситуация: зная уравнение эволюции, зная начальное состояние системы и все взаимодействия частиц, практически неважно вычислить её будущее, даже если система состоит из 30 электронов в потенциальной яме, а в распоряжении имеется суперкомпьютер с оперативной памятью, число битов которой равно числу атомов в видимой области Вселенной. И в то же время для исследования динамики такой системы можно просто поставить эксперимент с 30 электронами, поместив их в данные условия. Так и появилась идея использования квантовых процессов для практических вычислений. Первым эту проблему поднял русский математик Ю.И. Манин. Большое внимание к разработке квантовых компьютеров привлек лауреат Нобелевской премии Р.Фейнман. Благодаря его авторитетному призыву число специалистов, обративших внимание на квантовые вычисления, увеличилось во много раз.
Не буду останавливаться на устройстве квантового компьютера, скажу лишь, что стали возможны такие операции, не имеющие классических аналогов, например стало возможным задать операциюÖNOT так, чтобы ÖNOT*ÖNOT = NOT.
Вывод
Таким образом, мы на примерах разобрались в трудоемкости и громоздкости некоторых алгоритмов применительно к некоторым машинам, а так же в зависимости сложности логических функций от количества переменных, образующих эту функцию.
Литература
1. Гилл А. Введение в теорию конечных автоматов. М.: Наука, 1966.
2. Гэри М., Джонсон Д., Вычислительные машины и труднорешаемые задачи. М.: Мир, 1982.
3. Кузнецов О.П., Адельсон-Вельский Г.М., Дискретная математика для инженера. М.: Энергоатомиздат, 1988.
4. Манин Ю.И. Вычислимое и невычислимое. М.: Сов.радио, 1964.
5. И.фон Нейман Математические основы квантовой механики. М.: Наука, 1964.
6. Р.Фейнман Моделирование физики на компьютерах. Квантовый компьютер и квантовые вычисления. Ижевск: РХД, 1999.
7. Р.Фейнман Квантово-механические компьютеры. Там же.
8. В.В.Белокуров, О.Д.Тимофеевский, А.О.Хрусталев Квантовая телепортация – обыкновенное чудо. Ижевск: РХД, 2000.
9. А.Китаев, А. Шеня, М.Вялый Классические квантовые вычисления. М.: МЦНМО-ЧеРо, 1999.